We Timed Our Coding Agents. 92% of the Work Happened Before Code Was Pushed
We let an agent handle repetitive migration work, then logged every slice in five time buckets. The surprising part wasn't the code the agent wrote, it was where the loop spent its time, and what evidence we demanded before calling anything done. The second in a series of engineering notes from each::labs Recently, we had a production migration to do. A lot of the work was repetitive enough that it made sense to let agents handle the implementation loop. Not because we wanted to “trust AI with
We let an agent handle repetitive migration work, then logged every slice in five time buckets. The surprising part wasn't the code the agent wrote, it was where the loop spent its time, and what evidence we demanded before calling anything done. The second in a series of engineering notes from each::labs
Recently, we had a production migration to do.
A lot of the work was repetitive enough that it made sense to let agents handle the implementation loop. Not because we wanted to “trust AI with a migration,” but because we already had the important part in place: an end-to-end test suite and enough verification around the system to evaluate, steer, and reject the work once each slice was done.
The question we wanted to answer was not only whether agents could complete the migration work. We also wanted to understand where, inside our system, they actually spent their time.
Our intuition was that CI and review would be a large part of the loop. That is where many teams feel the drag: waiting for builds, waiting for feedback, pushing again, repeating.
But the log showed something different.
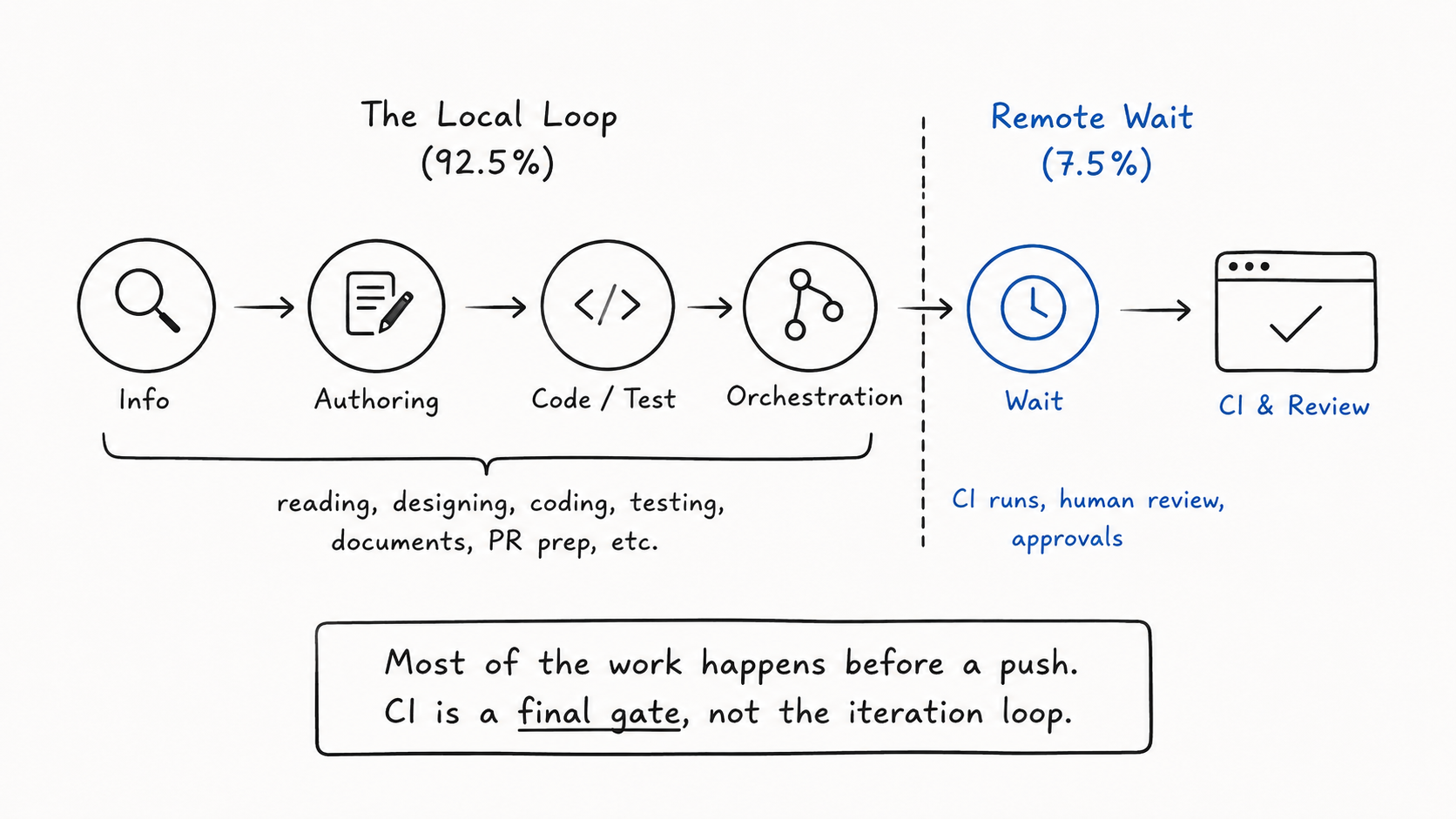
Most of the work happened before code was pushed.
The Number That Changed the Loop
Here is the headline from recent agent-assisted work, aggregated across tasks:
Local work ████████████████████████ 92.5%
Remote wait ██ 7.5% 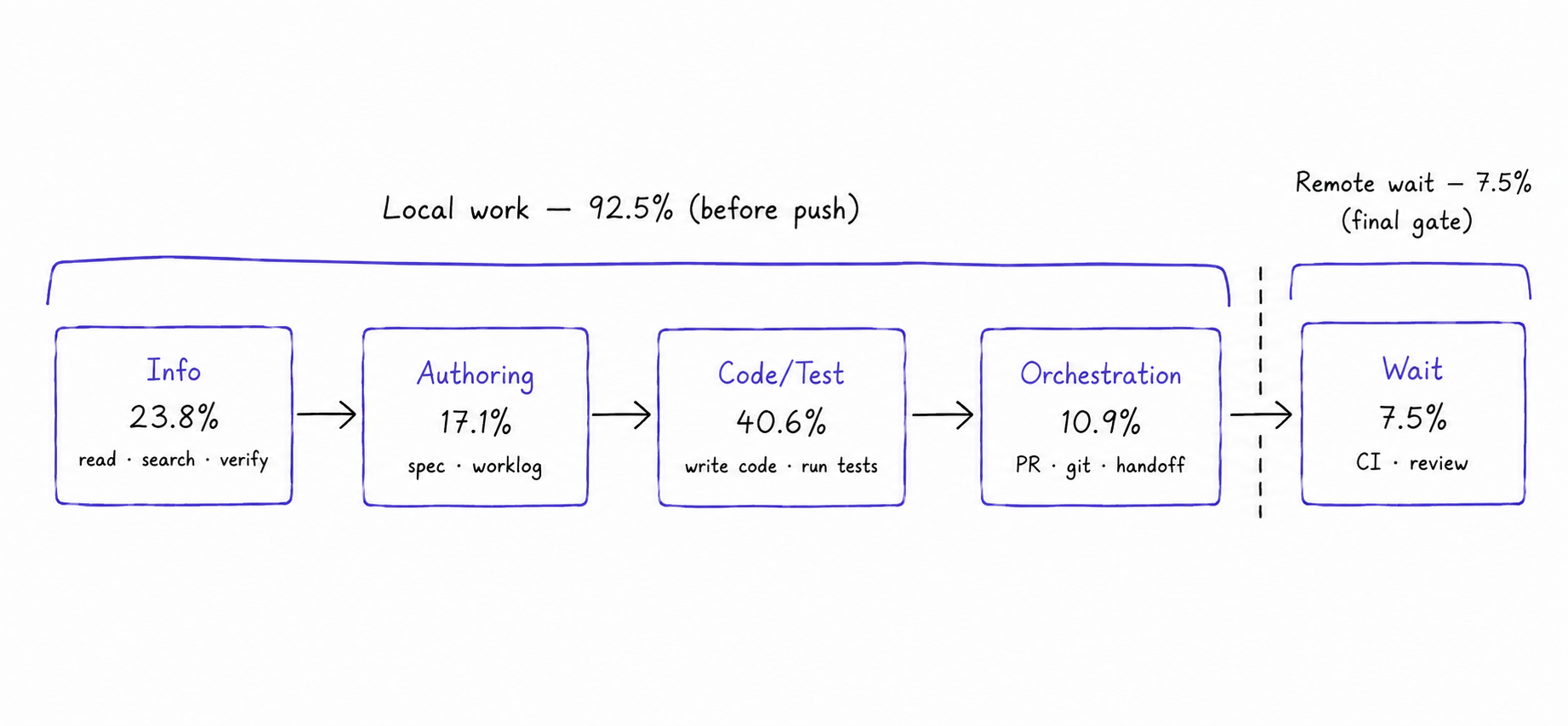
Local work is reading, designing, coding, testing, writing specs, preparing PRs — everything that happens on the machine before a push. Remote wait is CI and human review.
A loop that spends 92.5% of its time before push is a healthy one: CI is acting as a final gate, not as the iteration loop. The slow, shared, expensive resources — build, lint, ..., a reviewer's attention — aren't where the process is stuck. Whatever friction exists is local, and local friction is cheap to find and fix.
We only know that because we kept the log.
Our Logs: Five Buckets and a Rollup
The log is deliberately low-tech. Every meaningful slice of work gets an entry, and its time is split into five buckets that sum:
| Bucket | What it counts |
| --- | --- |
| Info | Reading, searching, understanding, verifying |
| Code/Test | Writing code, running tests and builds locally |
| Authoring | Writing or editing specs and worklogs |
| Orchestration | PR, git, ticket, and handoff work |
| Wait | Blocked on CI, a user, or a reviewer |An entry looks like this:
- Started 10:00 / agent — pricing page review
Info ~20m: read current implementation and related specs
Code/Test ~45m: implemented changes and ran local tests
Authoring ~10m: updated spec and worklog
Orchestration ~5m: prepared PR notes
Wait ~0m
Errors/rework:
Next action:Each file also has a rollup at the top, so effort aggregates across tasks instead of disappearing into "it took a while."
That is the whole instrument, a text file and a habit, not a tool you have to buy or build. You stamp start and stop at each boundary and write down where the time went. The buckets are chosen so that "where is the agent stuck?" always has a column to point at.
What the Log Told Us
Aggregated across recent tasks, the time splits like this:
Code/Test ████████████████████ 40.6%
Info ████████████ 23.8%
Authoring ████████ 17.1%
Orchestration █████ 10.9%
Wait ████ 7.5%Three things stood out.
The loop is local, not remote. Add up everything that isn't Wait and you get the 92.5% from the top. The iteration happens before push, not inside CI or review — the result we wanted. And now we can watch it hold or slip over time instead of guessing.
Reading is a quarter of the work. Info — understanding the existing code before touching it — is 23.8%, almost as large as writing code. On a migration that isn't waste; it's the opposite. But it's a number we can act on: the better the repository documents its own state — ledgers, decision logs, a clear definition of done — the less time every future slice spends rediscovering it. Investment in the system pays back as a smaller Info bucket.
The most valuable review happens before any code exists. In two separate specs, design-phase review caught serious problems before a single line was written — meaning zero Code/Test time went into building the wrong thing. One pricing spec went through three review rounds with zero lines of code, and in the process caught a hallucinated function that didn't exist, a missing identifier field, and an unsafe data tag. The cost was a little Info and Authoring time. The alternative is finding those problems after implementation, review, or rollout, which costs far more and can reach customers.
That last point is the argument for putting the system before the agent: the cheapest defect is the one caught in the spec, and the log is what proves the spec review is earning its keep.
The Harness Behind the Numbers
Our setup is strict and mature at this point, so the log makes sense. We generally proceed with:
One slice at a time. One implementation slice at a time, zero parallel writers, enforced by a task lock. The only parallelism allowed was read-only exploration: agents reading the old code, changing nothing. Slower on paper, but the throughput that matters is verified slices, not attempted ones.
A verifier after every meaningful check. Implementing and verifying pull in opposite directions — an implementer wants to finish, the mindset that makes optimistic assumptions. So after every build, test run, or compatibility check, a separate verifier read the evidence — the diff, the command output, the ledger — and returned PASS (next slice unlocks), FAIL (rework), or BLOCKED (escalate to a human). It could not accept "the tests pass" when the tests only checked the new code against itself.
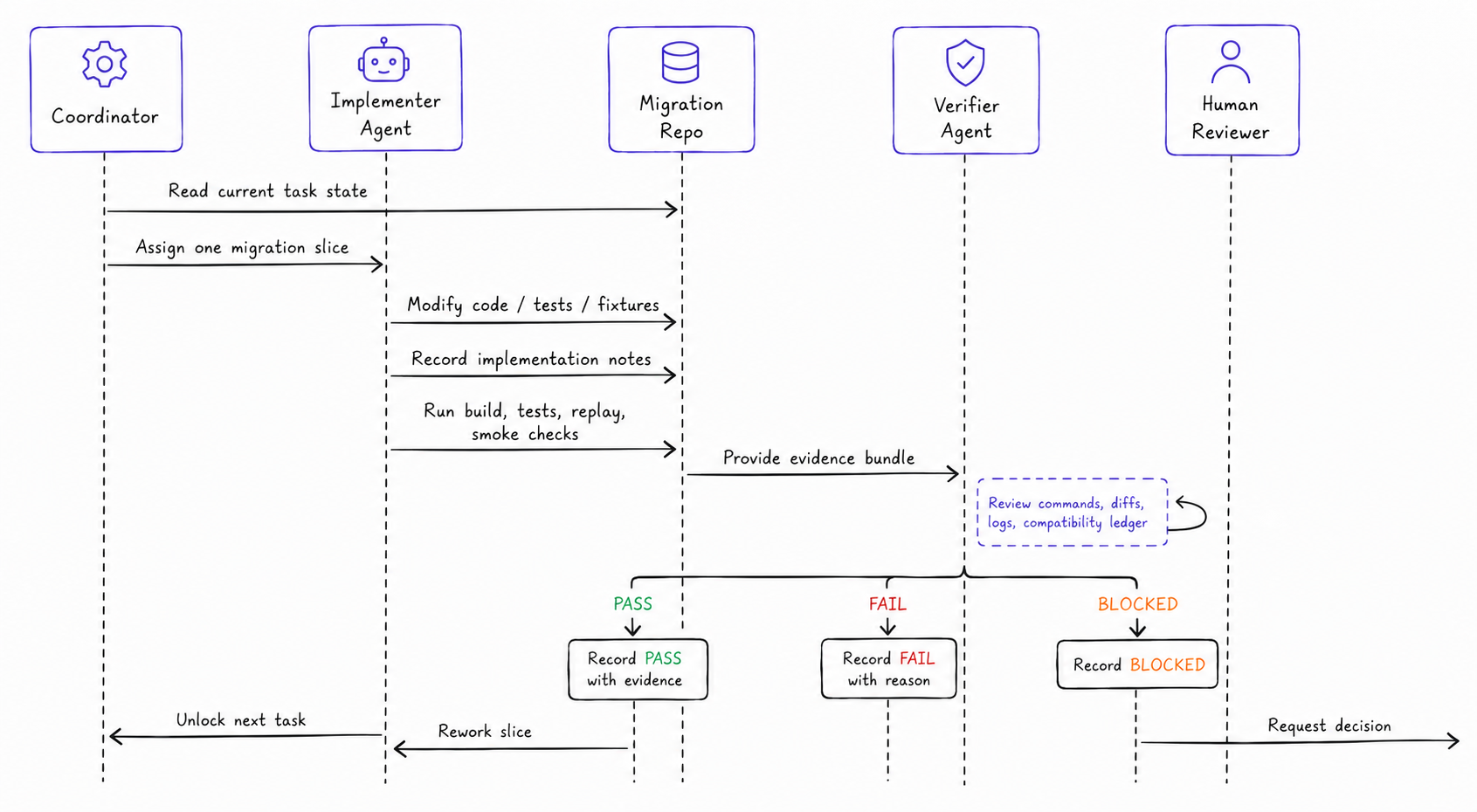
The slice that passed every check and was still wrong. Behavior bugs are difficult to catch. An example: in production, an async callback from a provider can land on a different instance than the one that started the job, or arrive after a restart — and that instance would find nothing, returning a 404 to a customer whose job had actually completed. The fix was durable storage. The verifier's job was to refuse to call the slice done until it was there.
The verifier wasn't perfect either, and that belongs on the record. One slice slipped a webhook with the wrong terminal status past its own check, caught only when the next slice failed over it; another time the read-only verifier overstepped and edited a test file, and the main loop caught it. A harness that can catch its own roles misbehaving is more trustworthy than one that assumes everyone is honest, and it still needs people watching.
The repository as the control surface. The first two mechanisms live in the third. The repo itself holds the operational truth: the task lock, the compatibility ledger, the decision log, the measurement ledger (where the time buckets live), the verifier protocol, replay fixtures, and the human approval gates. Acceptance criteria are written before the code for each slice, so "done" has a definition before anything can claim to meet it. Because all of this lives in the repo, anyone can resume an interrupted migration from what's already verified — no private context required. One rule keeps the agent's blast radius small: execution state changes only through eleven explicit transition handlers, the single place it mutates. Everything else is a read, and a read can't change anything.
More Numbers
We recorded the following hard counts:
- number of sequential implementation slices
- number of verifier states [PASS, FAIL, BLOCKED]
- number of human approved gates (around 20%)
Those are counts, not estimates. The five-bucket percentages (previous section) are softer: self-reported time estimates aggregated across recent agent-assisted work, not a benchmark, not a correctness proof. The log tells us where time goes; verification tells us whether the behavior is right.
To ensure (in case of a migration) the compatibility we had 34 e2e passes on different slices. It means that all our slices are e2e tested on dev, and we try for them to be always "backwards compatible" and "production-ready".
Where the Guarantees End
- Agents still make wrong assumptions. The harness doesn't make the agent correct; it makes its mistakes expensive to ship and cheap to find.
- A verifier can miss things on thin evidence. A green check over a small fixture set is a weak guarantee — one defect proved it by slipping to the next slice.
- Prompts are not hard boundaries. The read-only verifier broke its own rule once. The boundaries that held were in code and in the write path, not in instructions.
- The log is estimates, not proof. It tells us where time and friction go; it is not a correctness claim. Verification still runs against the diff and the checks.
The Long Game is About Measuring
Using agents on production code isn't a story about smarter agents. It's a story about whether the work has been made measurable enough to tell whether the agent helped at all — and where it needs help next.
The log was the cheapest instrument we built and one of the most useful. It told us the loop is mostly local, that reading is a quarter of the work, and that the highest-leverage review is the one that happens before any code exists. Each of those points to the same move: invest in the system around the agent — repository memory, earlier review, tighter specs — not in a bigger prompt.
The system is the harness around it, and a harness you can't measure is one you can't improve.