Making Fifty AI Providers Behave Like One Product
The goal was a system simple and legible enough to reason about. AI Agents became possible afterwards. The first in a series of engineering notes from Eachlabs from my side.
The goal was a system simple and legible enough to reason about. AI Agents became possible afterwards. The first in a series of engineering notes from Eachlabs from my side.
Author: Kevin Mamaqi Kapllani, Engineering Manager @eachlabs
Nobody really teaches you how to make fifty different AI providers behave like a single, unified platform.
From the outside, an LLM integration looks like calling an API endpoint. In production, it becomes an orchestration problem: polling, callbacks, terminal states, partial outputs, rate limits, weird errors, drifting schemas, cost rules, and customer support bottlenecks.
There's a fake version of this skill and a real one. The fake version treats AI integrations as simple API wrappers: write a client, map a few fields, return the output. The real version treats them as distributed execution systems requiring a lifecycle, durable state, error normalization, and a way to prove behavior end-to-end. The gap between these two is where most of the pain lives, because it dictates the answer to one recurring operational question: Can we explain what happened to this execution?
I'm starting a series of engineering notes from Eachlabs to write down how we actually build this—the architectural trade-offs, not the press releases. This first one is about executor-worker, the service that runs model executions against all of those providers. It's the clearest example of the pattern that runs through our engineering culture: build the stable parts with boring, known engineering, then let AI operate only where the system is bounded enough to verify.
Make Provider Chaos Legible
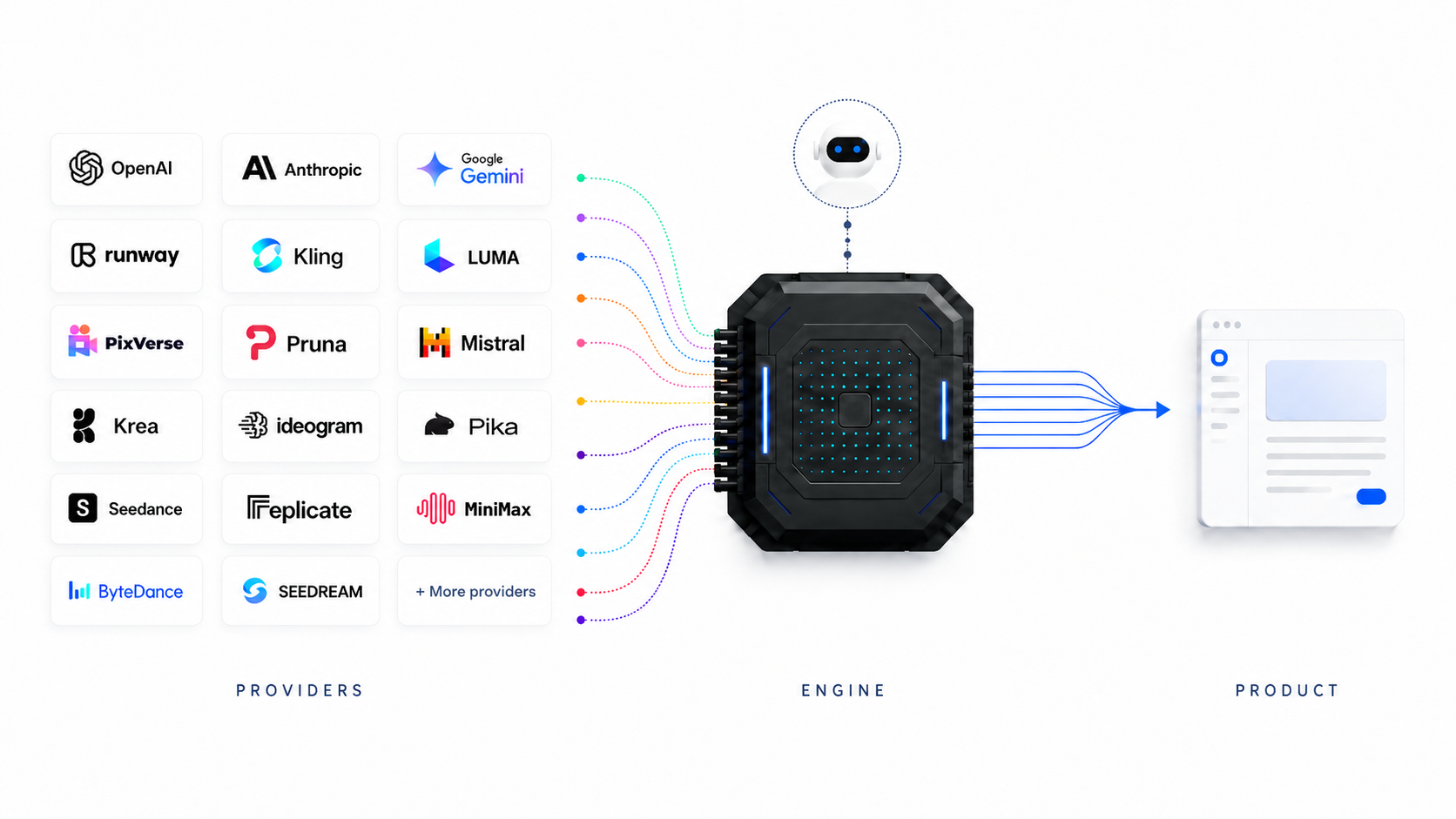
Ask the question that decides everything before you write a line of code: are we building an orchestration layer, or just collecting provider exceptions?
Collect exceptions and you get a folder of bespoke clients, each correct in its own way, none of them agreeing. Some providers return immediately. Some require polling. Some call back through webhooks. Some expose partial results. Some fail synchronously; some fail an hour later. Some hand you a provider job ID, some a model execution ID. Output shapes drift between versions. Error semantics differ. Cost only resolves after the job completes.
Now add the part nobody mentions: usage is uneven. A handful of models carry most of the real traffic. A long tail gets called occasionally and still has to bill correctly and deliver a result when it does. You can't hand-tune all of them, and most don't deserve it—but all of them have to behave predictably on a normal Tuesday.
A folder of exceptions has no shared answer to the questions that actually come up. Every operational question becomes a fresh investigation. Is this execution still running or did it fail? Was the customer charged? Why is this one stuck? Every provider answers differently, and that difference lands on whoever is doing support.
So the first job isn't smarter integrations or a fancy LLM gateway. It's making the chaos legible—giving every provider, however strange, the exact same observable shape so that support, product, and engineering can reason from the same facts.
Standardize the Lifecycle
We made the execution itself deterministic before we leaned on AI for any of it, because debugging fifty provider-specific execution models is a scaling problem, while debugging one execution model is an engineering problem.
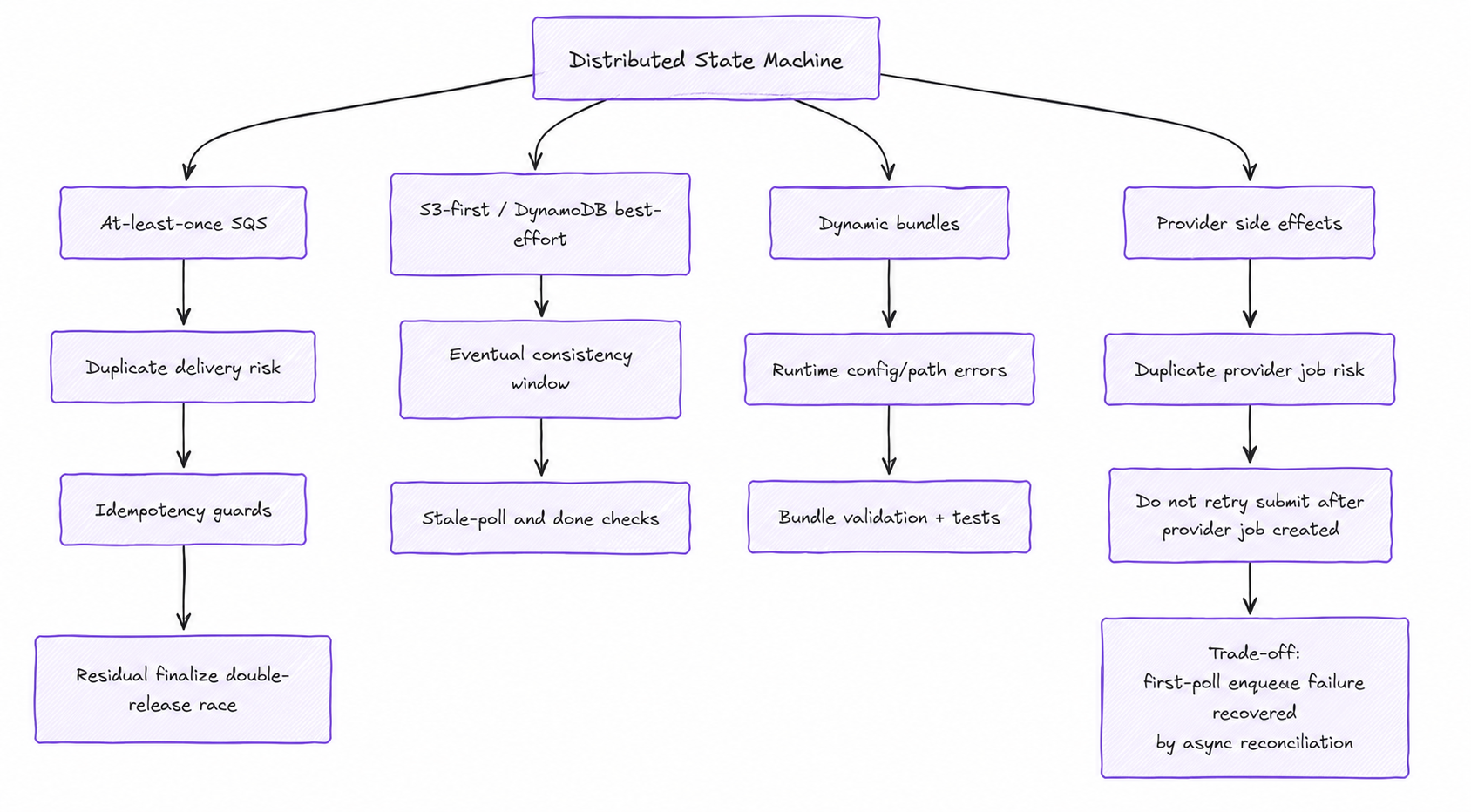
executor-worker behaves like a distributed state machine. Its transitions are SQS messages. Its durable memory is S3. Its fast lookup is DynamoDB. Provider variability is pushed out to declarative bundles and thin adapters.
Every execution advances through three actions:
submit -> poll -> finalize
submit sends the job: validate the request, resolve credentials, prepare input media, acquire flow-control capacity, run the createPrediction bundle, capture the provider's execution identity.
poll advances non-immediate work: load runtime and request state, check whether it's already done, enforce max-duration and cancellation guards, consume a callback if one arrived, call the provider if needed, then schedule another poll or complete.
finalize handles terminal delivery: load the result, compute cost, send the outcome onward to downstream billing and CRM systems, record degraded finalization if delivery fails, release flow-control capacity.
The queue isn't transport. SQS is the transition driver, the timer, the retry substrate, and the backpressure mechanism at once. Delay messages are waiting. Visibility timeout is in-flight processing. We didn't build a scheduler; we used the queue's primitives as the clock because it bounds the uncertainty of inflight work.
The three-action lifecycle: submit → poll → finalize.
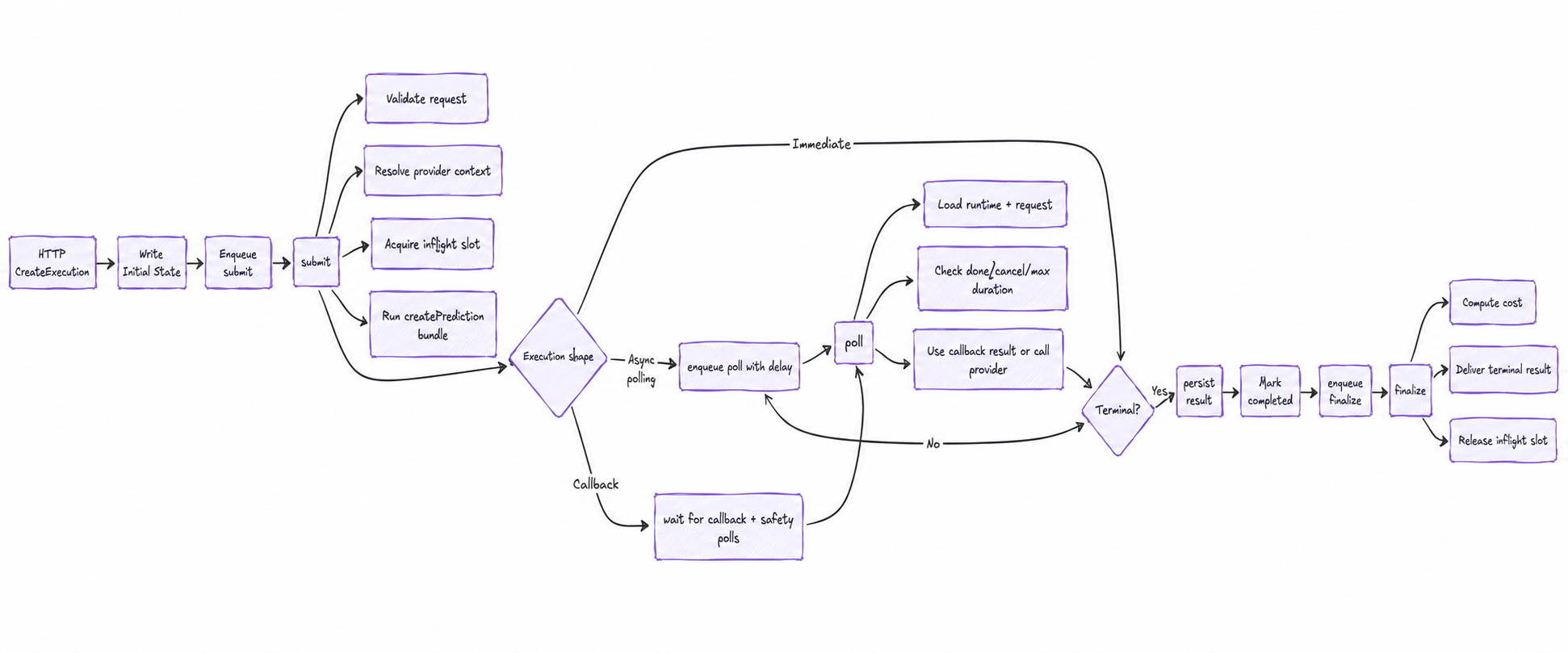
The same three actions absorb three provider shapes, chosen by the model's bundle: immediate (run in the request path), async polling (submit, then poll to terminal), and callback with safety polling (wait for the webhook, but keep polling so a missed callback never becomes an invisible stuck job). Providers differ in how they return results. The lifecycle stays the same. That is the whole point. We make fifty providers answer the same operational questions.
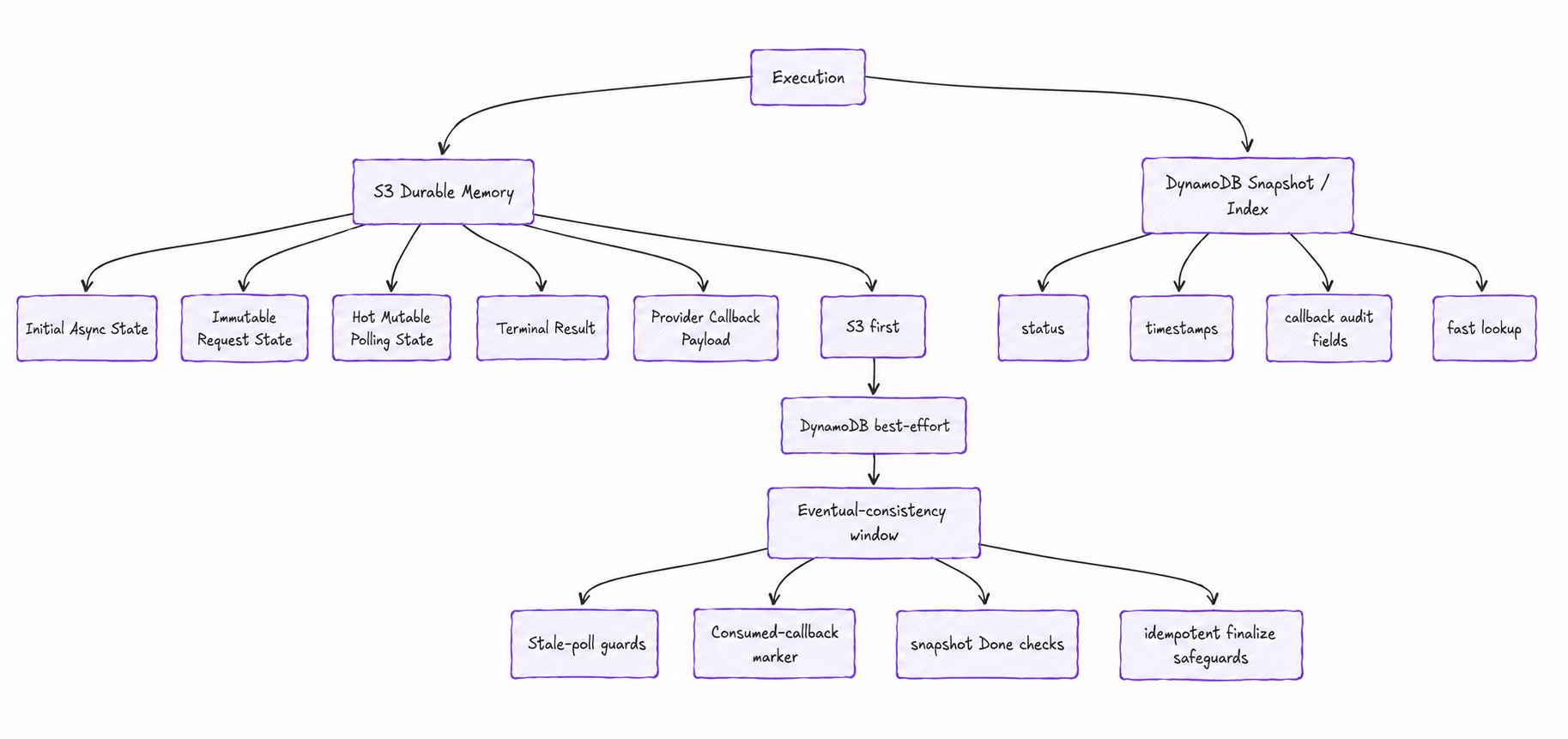
State lives in compressed S3 blobs—an immutable request, the hot mutable polling state, the terminal result, and any provider callback payload. DynamoDB is a snapshot/index for fast lookups and status, explicitly not the source of truth. We write S3 first and treat DynamoDB as best-effort, which opens an eventual-consistency window. We don't pretend it away; we guard it: stale-poll checks, consumed-callback markers, snapshot-done checks, idempotent release. This isn't about architectural purity; it's about making state transitions explainable.
State lives in S3; DynamoDB is a fast index, not the source of truth.
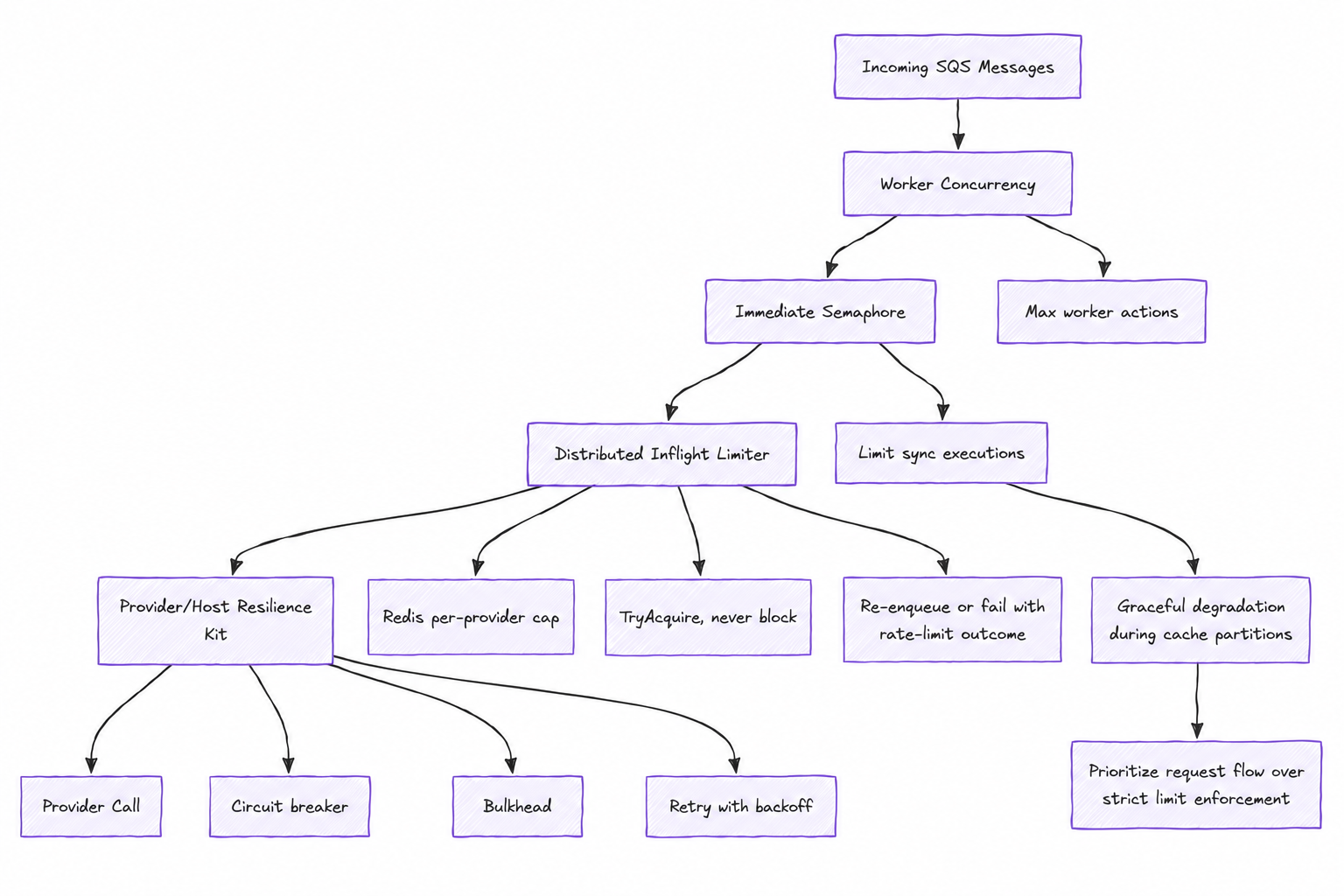
The machine also protects itself and its providers: worker concurrency, an immediate-execution semaphore, a Redis-backed inflight limiter per provider, and circuit-breaker / bulkhead / retry per host. None of this is novel, and that's the point. We aren't trying to admire the architecture. We are trying to make distributed execution measurable and controlled.
Four layers of flow control and resilience.
Turn Integrations Into Authoring
Most provider behavior is described, not coded.
A bundle is a declarative array of steps—http-request, transform-payload, transform-image, publish-event, conditional / for-each, file-handler, stop-execution. The engine iterates the same step model for every provider. Onboarding a model becomes a matter of describing it in data instead of writing a new service.
The behavior that genuinely can't be declared stays in thin adapters: classify errors, compute cost, normalize results, validate callbacks, extract job IDs. The variability that's left is corralled into a small named surface instead of smeared across the codebase.
That changes who can do the work. A newer engineer, or someone closer to product, can author or adjust a bundle and test a model against the same machine everything else runs on, because the boundaries are controlled. Bad configurations still fail, but they fail in a narrower, more predictable place.
The Platform Engineering Dividends
Building the machine isn't the reward. The reward is a shared operational language, and what that surface pays back in judgment and control every single day.
Shorten the loop. Are developers writing glue code, or validating a standard path? The value here isn't just speed—it's faster validation, faster rejection, and better learning.
- Before: Adding an integration took hours of reading docs, poking at responses, writing glue code, and chasing broken tests.
- After: The state machine and declarative bundles moved standard-path checks to minutes of structured validation—adjust the bundle, run the lifecycle, trigger the E2E test, inspect the normalized output, approve. The hours didn't vanish; they moved from re-implementing plumbing to confirming correctness and making actual engineering decisions.
Standardize failure. Can support, product, and engineering reason from the same facts?
- One taxonomy, applied everywhere: provider unavailable, rate limit, validation error, timeout, transient or fatal provider error, pipeline configuration error, callback failure, degraded finalization, partial result—instead of each adapter inventing its own failure language.
- The payoff isn't internal tidiness: It means fewer fresh investigations. Support and product can warn customers faster, without guessing, because the failure already carries a known shape by the time a human sees it.
Inspect the outputs. A green status is reassurance, not analysis.
- The signal: Each execution throws off more than a status code—normalized output, partial results, and the strange tail where a provider technically succeeded but returned something off.
- The leverage: Because every result is normalized to the same shape, you can pull a batch of failures, sort them into piles, and fix the biggest pile instead of opening ten provider formats by hand. One transcript of genuinely weird behavior teaches you more than the next point of success rate. You can't improve what you can't measure.
Keep knowledge close to code. Are docs decorative, or operational?
- The rot: For most integrations, documentation is a museum piece—written once, true for a week, quietly wrong by the next provider update.
- The fix: We keep knowledge next to the code and test it like anything else. CI and maintenance checks verify whether docs still match the implementation, whether E2E tests have drifted from real behavior, and whether the contracts are still usable by humans and automated tooling. Docs that are tested are docs you can trust, because the feedback loop is closed.
Keep Engineers in the Judgment Seat
We knew from day one that AI models would eventually get smart enough to help us maintain this system. But AI only becomes useful because the problem has been constrained enough that we can measure whether it actually helped.
Because every integration follows the same three-action lifecycle and most behavior is a bundle, an automated agentic workflow has concrete, bounded tasks: analyzing varying provider responses, proposing schema mappings to normalize outputs against our known contracts, comparing an integration against the expected lifecycle, and generating replay fixtures.
These are the high-variance, low-leverage tasks—the places humans burn hours on translation. That's where generative AI helps. Correctness and final judgment stay with developers.
This is the line I keep coming back to:
We do not use AI to avoid engineering discipline. We use engineering discipline to decide where AI can safely help.
The timing matters too. For most of this system's life, we leaned entirely on deterministic state-machine design, because agents simply weren't reliable enough to put near production executions. As models improved, we could start taking them seriously in this workflow—but only because there was finally a stable, inspectable system for them to operate on.
So, plainly: the state machine came first. The agentic layer only became useful because the execution domain had already been standardized, bounded, and made measurable.
Which answers the question under all of this: are we using AI to avoid engineering, or using engineering to make AI useful? The machine is the answer. It moves engineers off the plumbing and into the judgment seat.
Name the Sharp Edges
I don't want this to read as a success story with the edges sanded off. The design has real costs, and naming them is part of why I trust it. At least then the risks are visible enough to monitor.
There is no single declarative transition table—the state machine is real, but you can't read it in one file. Runtime and request state must be kept in sync by hand. Correctness depends on guards over an intentionally eventually-consistent store, and those guards are load-bearing.
SQS is at-least-once. After a provider job is created, we must not let a failed first-poll enqueue trigger a submit retry, because that could create a duplicate job. In that narrow window, an execution can instead get stranded in a submitted state and require asynchronous reconciliation. Finalize has a residual race around releasing inflight capacity if two finalizers load the releasable scope before either persists the cleared one.
Polling adds baseline queue traffic and latency for providers without callbacks. The bundle model uses dynamic maps and path resolution, which moves some errors from compile time to runtime. And some implicit product knowledge—what an execution is, how terminal states map, when cost finalizes—should be documented more explicitly before it hardens into hidden coupling.
None of these invalidate the architecture. They're simply the price of the trade-offs. The discipline is engineering the guards, knowing where the system is blind, and retaining operational control.
The Long Game
The trend is AI integration scale is about adding smarter agents.
It actually starts with a legible execution machine. Once executions are bounded—one lifecycle, durable memory, declarative bundles, normalized errors and outputs—agents can actually help with the repetitive, uncertain parts. Before that, they're just one more unreliable router over chaos.
The future here is not "AI replaces integration engineers." It's engineers making decisions based on observable facts, and AI helping operate the repetitive loops around them.
That's the throughline I want this series to be honest about, and it's what the next articles build on. Standardizing execution solved the machine side. It didn't solve the human loop around it—support, triage, integration readiness, delivery drift—or the harder question of letting agents help change production systems without losing control of correctness.
So next I want to write about what this stable surface made possible: putting scoped, operational agents into the team's daily workflow, and approaching a migration as a measurable engineering problem instead of a rewrite. Both only became reasonable because the execution domain was made legible first.
The goal was never agents. The goal was a system simple enough to reason about. Agents became possible afterwards. Stable engineering first. AI where it genuinely reduces repetition and ambiguity. Developers still holding correctness. None of it is magic, and that is exactly why it holds up.