GPT Image 2 Just Leaked!
GPT Image 2 didn't get a press release. It didn't get a launch event. Three codenames showed up on a public leaderboard, the community started testing, and within hours it was everywhere. The outputs people were sharing weren't subtle improvements. They were a different category of result entirely. Not incrementally better. Different. Here's everything we know so far, including a breakdown of the real leaked examples that caused all the noise. What Is GPT Image 2? OpenAI's image generation t

GPT Image 2 didn't get a press release. It didn't get a launch event. Three codenames showed up on a public leaderboard, the community started testing, and within hours it was everywhere. The outputs people were sharing weren't subtle improvements. They were a different category of result entirely. Not incrementally better. Different.
Here's everything we know so far, including a breakdown of the real leaked examples that caused all the noise.
What Is GPT Image 2?
OpenAI's image generation timeline has moved fast. DALL-E led the early years. Then GPT Image 1 arrived, shifting to an autoregressive architecture and setting a new bar for instruction-following in image generation. GPT Image 1.5 followed shortly after, polishing the rough edges and landing at the top of the LM Arena leaderboard.
GPT Image 2 is the next step and based on what's leaked, it's not built on GPT4o's image pipeline. Community testers and analysts who dug into the backend believe it's an entirely new, standalone architecture. That matters because it means this isn't a patch on top of existing infrastructure. It's a dedicated image generation system designed from the ground up.
OpenAI hasn't confirmed a release date. But the fact that it appeared on a public evaluation platform even under aliases tells you a launch is close. That's exactly how Google handled Nano Banana Pro before its release: anonymous Arena testing, community discovery, viral traction, then an official rollout. OpenAI appears to be running the same playbook.
How It Leaked: The Tape Models
Early April 4, 2026 is when things got interesting. Three models turned up on LM Arena with names nobody recognized: maskingtape-alpha, gaffertape-alpha, and packingtape-alpha. No company attached. No explanation. Just prompts going in and outputs coming out
One of the developers was among the first to identify them publicly. His post on X noted they had "extremely good world knowledge and great text rendering" and suggested they might outperform Nano Banana Pro. A venture investor echoed this, posting her own tests with prompts like "average engineer's screen" and "young woman taking selfie with Sam Altman." Both produced results with an unusual level of contextual specificity.

The models were pulled from Arena within hours of being publicly identified. That's the giveaway. If these were random experimental models from an unknown lab, they'd stay up. They were pulled because someone didn't want them identified yet. The AI community noticed anyway.
What Makes GPT Image 2 Different
Text Rendering That Actually Works
If you've used image generators for any stretch of time, you already know the text problem. Letters bleed into each other, words get scrambled, and whatever text does appear tends to hover over the scene like an afterthought rather than belonging to it.. GPT Image 1.5 improved this significantly. GPT Image 2 appears to have largely solved it.
Community testers reported that text inside complex scenes UI screenshots, product mockups, signage rendered cleanly and correctly. The words sat in context, not on top of it. For anyone who's tried to generate marketing assets or interface mockups with earlier models, that's a practical difference that changes what the tool is actually useful for.
World Knowledge That Shows
This is where GPT Image 2 surprised people most. One tester prompted the model with "average engineer's screen" and got back a monitor setup that looked like it came from a real software developer's desk with realistic browser tabs, familiar UI patterns, and contextually appropriate content on the screen. That's not just artistic style. That's knowledge about what the world actually looks like.
Another tester prompted "young woman taking selfie with Sam Altman" and got a recognizable, contextually accurate result. The model clearly has dense training data around specific real-world contexts and public figures, which translates into generations that feel grounded rather than generic.
Photorealism at a New Level
Several testers reported that some outputs were difficult to identify as AI-generated. Beach selfies with natural lighting, correct hand rendering, accurate sunglass reflections. One of the more cited examples was a Minecraft scene set in Manhattan first-person view, realistic urban textures, gameplay-accurate framing where maskingtape-alpha beat every model in the comparison, including Nano Banana Pro.
The yellow tint that affected GPT Image 1 outputs also appears to be gone. Color rendering is reportedly more neutral and accurate across different lighting scenarios.
UI and Screen Capture Accuracy
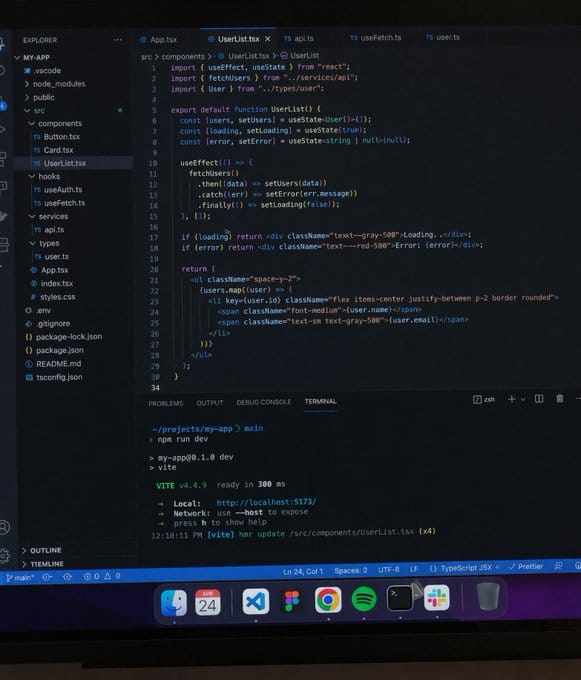
The leaked models showed particular strength on interface screenshots and game UIs. A prompt for "top-down strategy game about optimizing an AI data center" reportedly made Nano Banana Pro look a full generation behind. This suggests the training data included a significant volume of screen recordings and UI captures which makes the model unusually capable for anyone building product mockups, app demos, or game assets.
Real Examples We Analyzed
The range of outputs that circulated after the Arena window was wider than most people expected. A few highlights worth walking through.
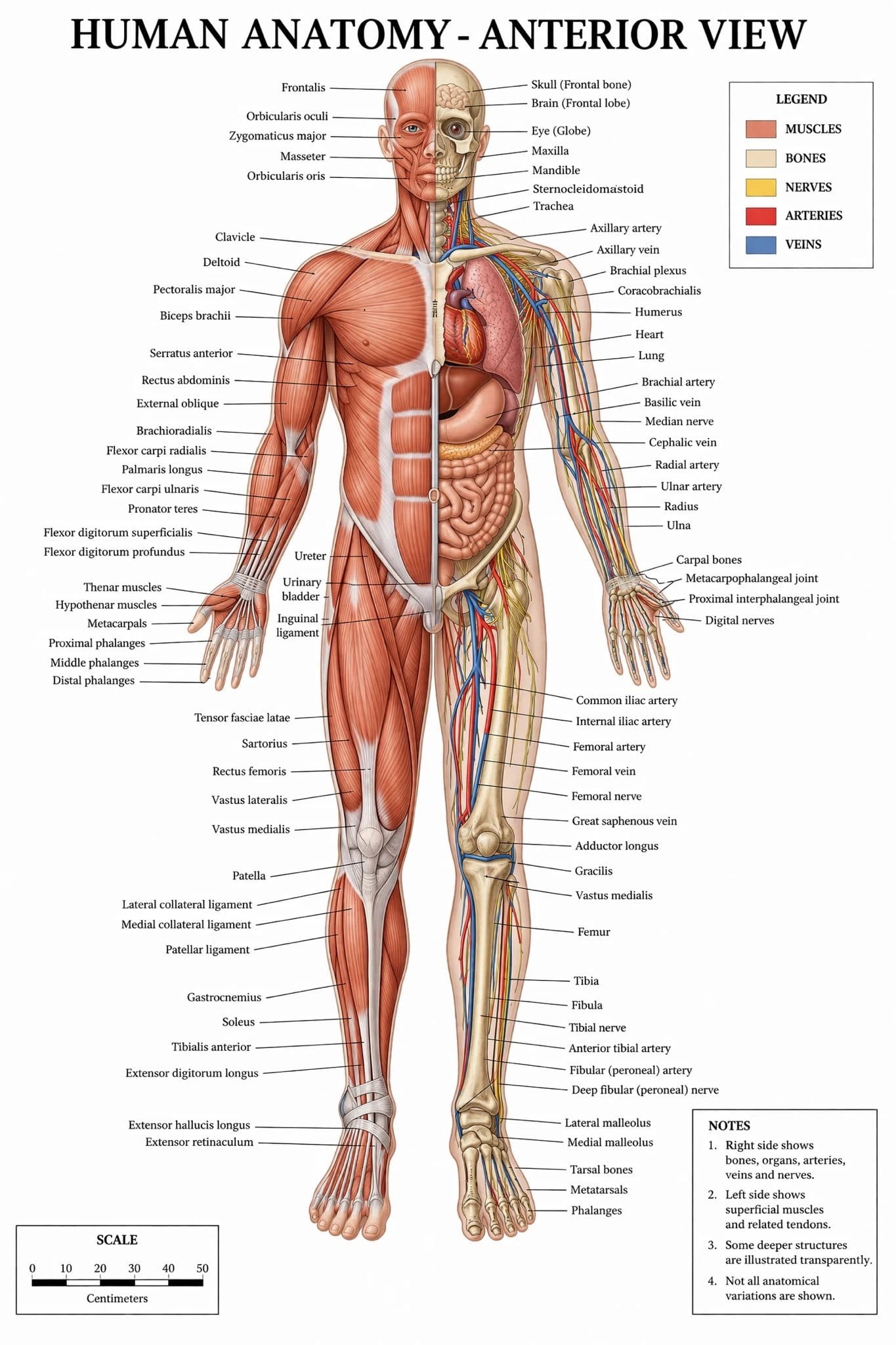
Human Anatomy Diagram
A full body medical illustration came out with musculature, vascular detail, and anatomical labels that sat exactly where they should. Most models either get the anatomy plausible-but-wrong or mangle whatever text is embedded in the image. This one did neither it read like a page pulled from a clinical reference.
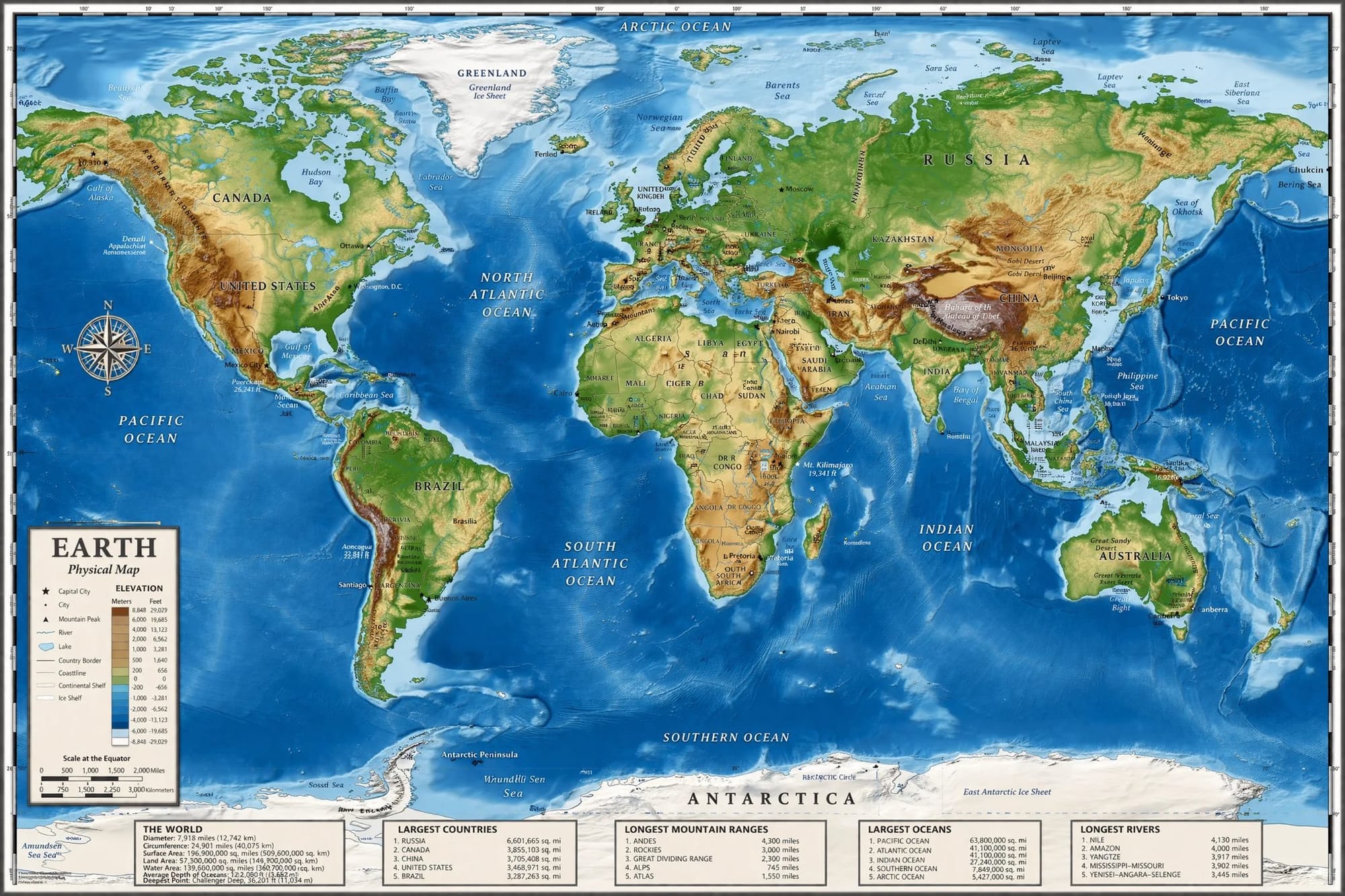
World Map with Geographic Accuracy
Someone prompted a physical world map and got back continent labels, ocean names, and topographic shading that looked like it came from a cartography studio. What caught people's attention wasn't just how clean it looked it was that the spatial relationships were correct without being explicitly specified in the prompt.
Real Store Interior (Bath & Body Works)
Two views of a retail interior came out with product shelving, store signage, and lighting that were hard to call AI at first glance. The brand details were right. The store layout matched how that type of space is actually organized. Useful output for retail mockups or merchandising planning without any post-processing.

YouTube Style Interface Screenshot
The YouTube homepage generation is the one that made people stop and look twice. Channel icons, video thumbnails, view counts, readable title text all laid out in the right hierarchy. It wasn't immediately obvious this wasn't a real screenshot. If you're building media decks or content strategy presentations, that's a prompt that goes straight into your workflow.
What tied all of these together was a consistent pattern: the model clearly trained on dense, specific real-world data, and the outputs show that in ways that go past surface level polish.
Why the Timing Matters
OpenAI shut down Sora on March 24, 2026 roughly a month before these models appeared on Arena. The stated reason was compute reallocation toward "world simulation research." The practical reality was that Sora was expensive to run and losing users fast. Shutting it down freed up significant GPU capacity.
That freed capacity had to go somewhere. A next generation image model is the obvious answer. The timing between the Sora shutdown and the Arena appearance of the tape models isn't coincidental. It suggests OpenAI moved quickly once the compute became available, and a public release is likely coming in the April to June 2026 window.
DALL-E 2 and DALL-E 3 are also being retired on May 12, 2026, which means developers currently using the older API endpoints need to migrate anyway. GPT Image 2 would give them something worth migrating to.
How to Use GPT Image 2 on Eachlabs
When GPT Image 2 lands on Eachlabs, you won't need to set up an API or juggle multiple accounts to get to it. It'll sit alongside the other models on the platform, so you can run comparisons, iterate quickly, and plug it into whatever you're already building all in one place.
From what the leaked examples show, the prompts that tend to produce the strongest results are specific ones. This model knows what things actually look like real stores, real interfaces, real environments. Vague prompts leave that on the table. "Product shot on a pharmacy shelf next to competing brands" will get you somewhere. "Product on white background" won't push it. Same logic applies to UI work: the more context you give, the more the model has to work with.

Tips for Getting the Best Results
Prompt for Specificity, Not Just Aesthetics
The leaked examples that impressed people most were responses to specific, contextually grounded prompts. "Average engineer's screen" worked because it referenced something the model has concrete knowledge about. Abstract prompts like "futuristic interface" leave too much to interpretation. The more specific your reference point, the more the model's world knowledge kicks in.
Use Real-World References When You Can
If you want a store interior, name the type of store. If you want a UI screenshot, reference a real platform or pattern. GPT-Image-2 appears to have been trained on large volumes of real-world visual data, and outputs are strongest when prompts align with things that actually exist in that training data.
Request Text Explicitly and Position It
Text rendering is a headline strength of GPT-Image-2, but you still need to ask for it. If your image needs text labels, signage, or UI copy, include them explicitly in your prompt with positioning context. "Label on the left side reading 'Cardiopulmonary'" is more reliable than hoping the model figures out placement on its own.
Iterate on Aspect Ratio
Early community testers found that including "Format: 16:9" in prompts reliably triggered widescreen output. GPT-Image-2 is expected to natively support higher resolutions and multiple aspect ratios. Experimenting with aspect ratio early in your workflow will save iteration time later.
Wrapping Up
GPT Image 2 leaked before it launched, and the early examples are genuinely impressive. Text rendering, world knowledge, photorealism across each of those categories, the community consensus from the Arena testing window is that GPTImage 2 is a step change from what currently exists. Whether it displaces Nano Banana Pro as the photorealism benchmark will depend on sustained testing once the model is publicly available. But if the leaked examples are representative of what the full release will deliver, the image generation landscape is about to look very different. Keep an eye on Eachlabs once GPT Image 2 goes live, you'll be able to put the leaked claims to the test yourself.
Frequently Asked Questions
What are maskingtape-alpha, gaffertape-alpha, and packingtape-alpha?
They're the codenames under which GPT Image 2 was stress-tested on LM Arena before any public announcement. The tape naming fits OpenAI's existing GPT-Image naming pattern, and the fact that all three got pulled within hours of being identified tells you most of what you need to know about where they came from. Google ran the exact same play with Nano Banana Pro anonymous Arena testing, community discovery, then an official launch once the Elo scores made the case.
How does GPT-Image-2 compare to the current version?
Meaningfully better in the places that actually show up in real work. Text sits inside scenes correctly instead of floating over them. The model's world knowledge is noticeably denser it seems to understand what specific environments, interfaces, and objects actually look like, not just a plausible approximation. And unlike GPT Image 1.5, which was built on top of GPT 4o's image pipeline, this one appears to be a standalone architecture designed specifically for image generation.
When will GPT-Image-2 be officially released?
OpenAI hasn't said. The Arena testing happened in early April 2026, Sora shut down just weeks before that, and DALL-E 2 and 3 are being retired on May 12 so there's a real forcing function here for developers who need somewhere to migrate. Most people tracking this expect an announcement before June. Once GPT Image 2 is available on Eachlabs, you'll be able to test it directly on the platform.