The Guide to AI Video Generator from Images vs Text to Video AI
A Complete Analytical Framework for All Users and Industries Artificial intelligence has redefined the video creation landscape by removing the need for complex editing software, professional equipment, or advanced production skills. Two categories of AI driven video systems have become foundational in this transformation Image based AI video generators Text to video AI generation models Although both automated video creation, they operate using fundamentally different input structures, pr
A Complete Analytical Framework for All Users and Industries
Artificial intelligence has redefined the video creation landscape by removing the need for complex editing software, professional equipment, or advanced production skills. Two categories of AI driven video systems have become foundational in this transformation
Image based AI video generators
Text to video AI generation models
Although both automated video creation, they operate using fundamentally different input structures, processing mechanisms, and output patterns. This guide delivers a technical, research informed, and universally applicable breakdown of both systems, enabling any user to select the correct model for their workflow with professional accuracy.
Content references from your uploaded document are included where necessary.
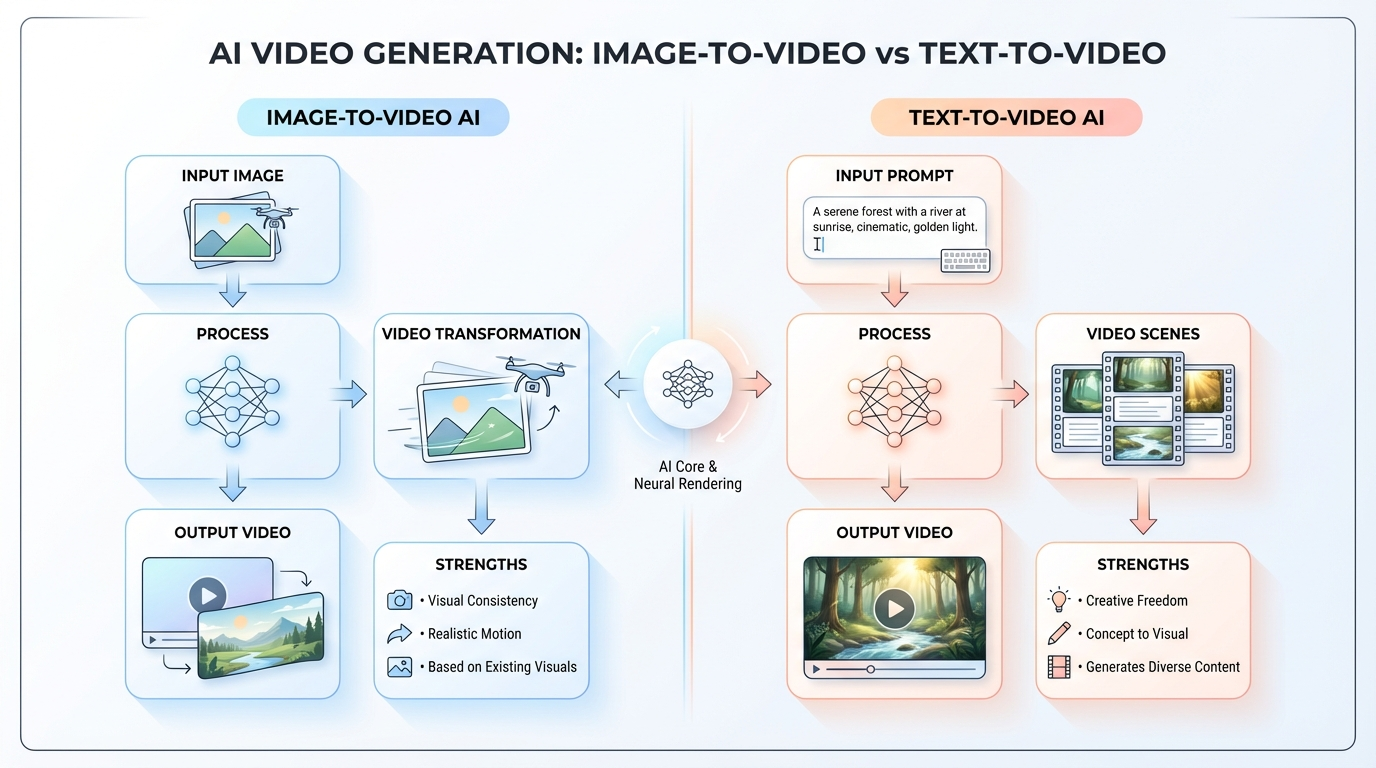
1. AI Video Generator from Images
A Technical Overview
An AI video generator from images is a visual centric system that transforms static images into motion enhanced video sequences. The model relies on computer vision, motion synthesis, and generative animation algorithms to simulate camera movement and temporal flow.
Core Mechanism
These systems typically combine;
• image feature extraction
• motion vector prediction
• frame interpolation
• dynamic transition generation
• music and text overlay integration
The model analyzes each image, identifies key visual anchors, and applies controlled motion paths to create movement such as zoom in, zoom out, pan, tilt, and parallax effects.
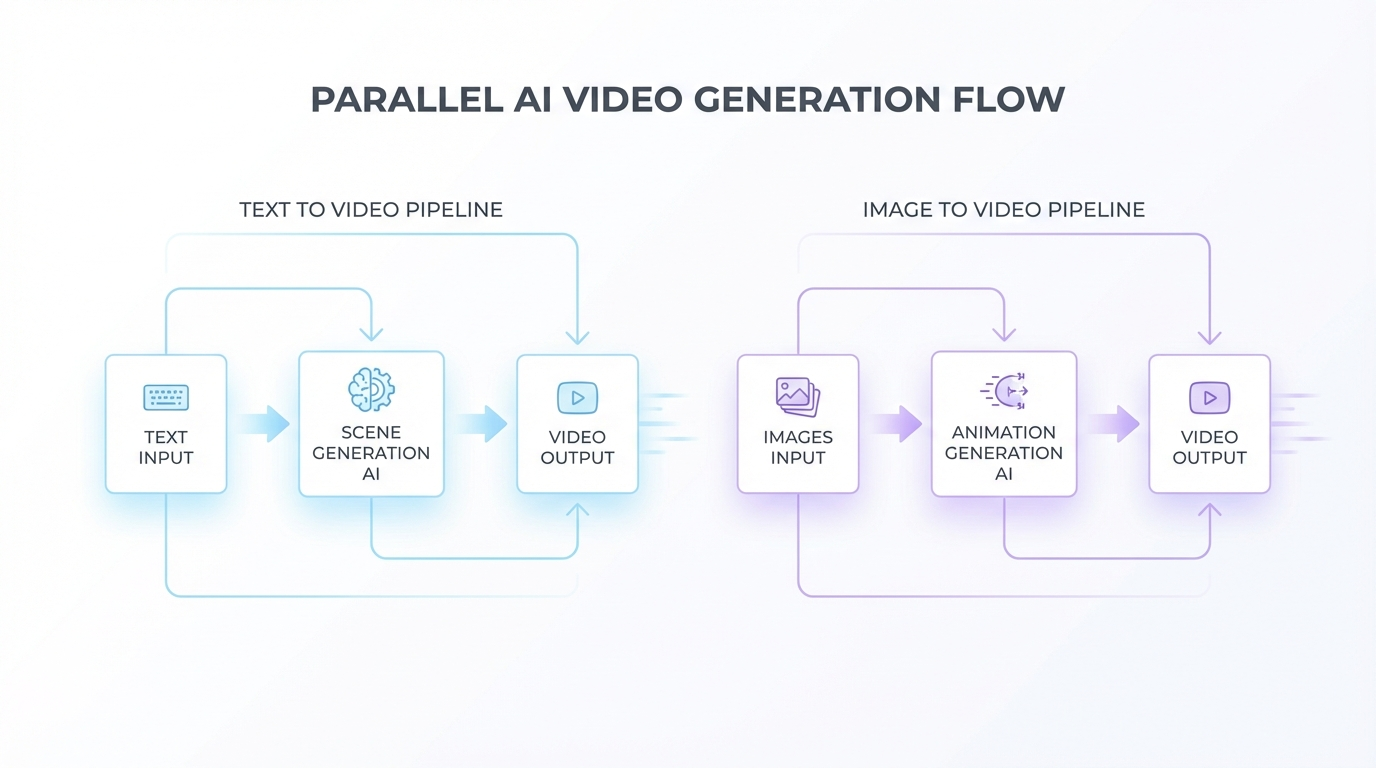
Workflow
- Image upload
- Selection of model or template
- Optional script or caption insertion
- Real time preview
- Output rendering
High visual fidelity
Output maintains the quality of the original images.
Optimized for product or portfolio content
Ideal for presentations that rely heavily on visuals.
Low cognitive load
Users do not need to write scripts or structure narrative elements.
Ideal Applications
• digital portfolios
• ecommerce product showcases
• travel and photography reels
• brand highlight videos
• event recaps
• artistic slideshows
This model excels when the primary asset is already visual.
2. Text to Video AI Generator
A Technical Overview
A text to video generator is a language driven system that interprets natural language input and maps it to corresponding visual scenes. Unlike image based models, this architecture synthesizes or selects visual elements based entirely on semantic understanding.
Core Mechanism
These systems combine
• natural language processing
• semantic scene decomposition
• visual concept retrieval
• motion graphics generation
• synthetic narration and audio design
The model parses the user’s script, segments it into discrete scenes, and assigns visuals based on context, tone, and described actions.
Workflow
- Script composition
- Selection of text to video generation model
- Scene level modification
- Rendering and export

Strengths
Narrative centric construction
Output focuses on message delivery and conceptual flow.
Zero dependency on visual assets
Perfect for users who lack images or footage.
Scalable for complex communication
Useful for training videos, explainers, and educational content.
Ideal Applications
• instructional and training modules
• product explainers
• storytelling and concept videos
• academic presentations
• marketing campaigns
• corporate communication
This model excels when the core asset is verbal or conceptual.

3. Comparative Technical Analysis
Input Modality
Image based
Requires photographs or graphical assets
Text based
Requires natural language script inputs
Processing Focus
Image based
Focuses on animation and visual enhancement
Text based
Focuses on semantic interpretation and scene generation
Output Characteristics
Image based
Visually rich, motion enhanced, photography centric
Text based
Narrative oriented, scene segmented, explanatory
User Profile Fit
Image based
Users with existing visual material
Text based
Users with ideas who need visualization
4. Step by Step Technical Guide
How to Implement Each Model Effectively
A. Implementation of Image Based AI Video Generators
- Curate high resolution images
- Import into the selected model
- Adjust motion parameters and transitions
- Insert textual elements if required
- Validate timing through preview
- Render and export in chosen resolution
B. Implementation of Text to Video AI Systems
- Compose a structured script with clear scene boundaries
- Input the text into your chosen model
- Refine style, tone, and pacing
- Validate generated scenes
- Export in final format
5. Decision Matrix
How Any User Can Choose the Correct System
Choose Image Based AI When
• visual assets are the primary material
• content needs to highlight aesthetics
• speed and ease are top priorities
• no complex explanation is required
Choose Text to Video AI When
• you want message driven communication
• visual assets are unavailable
• storytelling or explanation is essential
• you need flexibility in content style
Optimal Strategy
A hybrid workflow produces the strongest results
• Image based for visuals
• Text based for explanation
Together they create a complete production ecosystem.
Conclusion
AI video generators have redefined accessibility and scalability in modern video production. Image based systems offer precision in visual enhancement, while text to video models deliver strength in narrative construction. Understanding the structural differences allows any user, regardless of technical background, to select the correct model and produce professional grade results.