All Rumors About GPT Image 2
In our previous blog, we broke down the GPT Image 2 leak in full: the Arena codenames, the technical architecture clues, and what the upgrades suggest about OpenAI's next generation image model. Now let's talk about something different: the actual human reaction. Because what happened on X after the leak broke was one of the more electric AI moments of 2026, and it deserves its own look. It didn't start with a press release. It started with screenshots that people couldn't explain. The Leak T

In our previous blog, we broke down the GPT Image 2 leak in full: the Arena codenames, the technical architecture clues, and what the upgrades suggest about OpenAI's next generation image model. Now let's talk about something different: the actual human reaction. Because what happened on X after the leak broke was one of the more electric AI moments of 2026, and it deserves its own look.
It didn't start with a press release. It started with screenshots that people couldn't explain.
The Leak That Kicked Everything Off
If you've been following along, you already know the setup. Three models appeared on LM Arena for blind testing under the names maskingtape-alpha, gaffertape-alpha, and packingtape-alpha. They were pulled relatively quickly once the identification posts started spreading, but not before the community had captured enough output to fuel days of conversation.
The story spread in waves. First the discovery, then the examples, then the debate about what it all meant. Each wave brought in a different segment of X's AI community, and each one had something distinct to say about GPT Image 2.
The First Posts: Before Anyone Knew What They Were Looking At
@Angaisb_ was one of the first voices on X pointing to unusual activity in the Arena rankings. Something was different about these models, even before anyone had matched the codenames to OpenAI. @chatgpt21 picked this up early too, sharing what was circulating before the full picture had emerged.

Then @synthwavedd posted some of the earliest outputs. Real examples. And they stopped people mid-scroll. Not because they were flashy, but because they were quiet in a way that AI images usually aren't. No obvious artifacts. No uncanny wrongness lurking in the corners. Just outputs that looked like they came from a camera, not a model.

How @blakeir Put It
@blakeir, Blake Robbins, posted what became one of the most-quoted takes on the leak:
"people are speculating GPT-Image-2 is testing on @arena. the early examples being posted are pretty mind-boggling. all three of these images are AI generated."
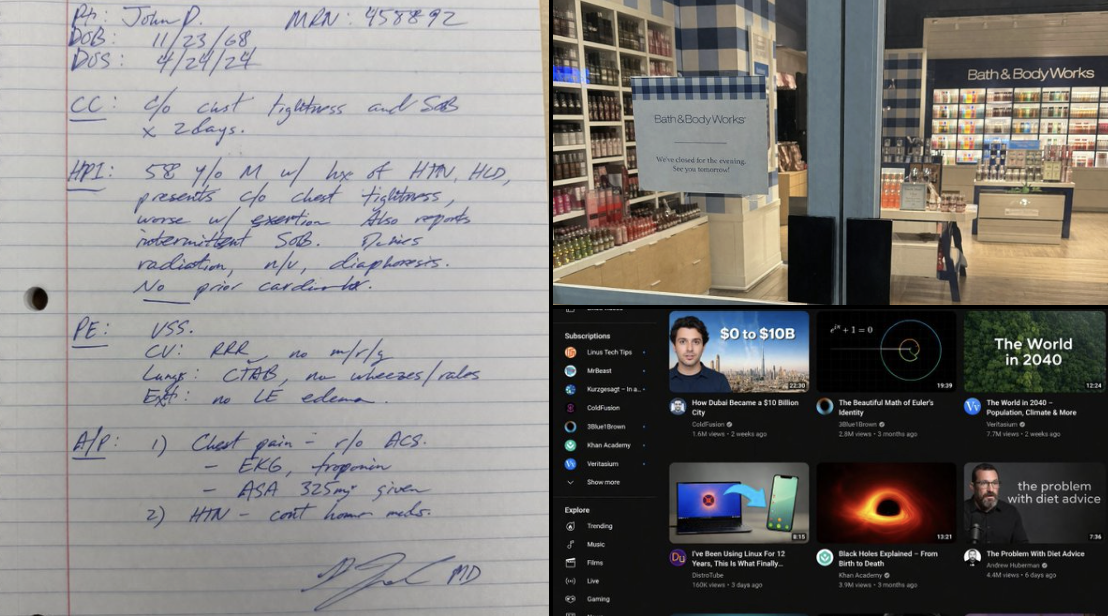
He credited @synthwavedd for surfacing the initial examples. And "mind-boggling" turned out to be accurate, not hyperbole. Multiple people in the replies tried to spot the AI tells and came up empty. That doesn't happen often. It's the kind of reaction that signals something has actually changed, not just iterated.
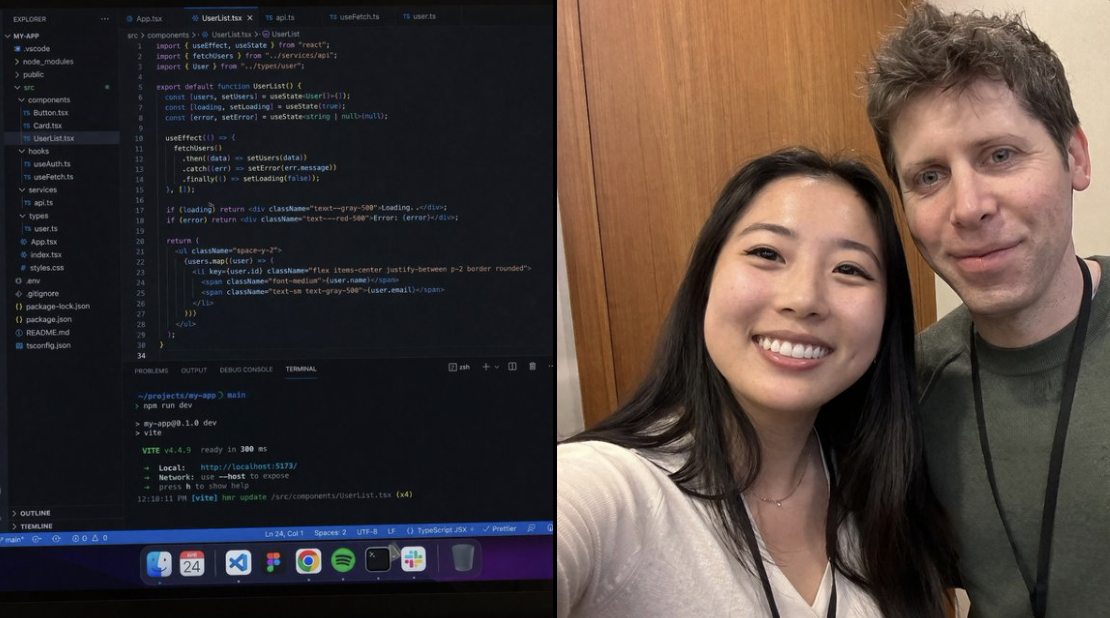
@venturetwins followed shortly after with her own tested examples. The level of contextual awareness and fine detail in the outputs she shared made clear this wasn't GPT Image 1.5 with a new filter. Something architecturally different seemed to be happening.
The Post That Made It Explode
@levelsio, Pieter Levels, brought the story to a significantly larger audience:
"OpenAI's new image model GPT-Image-2 has leaked. It seems to have extremely good world knowledge and great text rendering. It's on @arena under code names: maskingtape-alpha, gaffertape-alpha, packingtape-alpha."
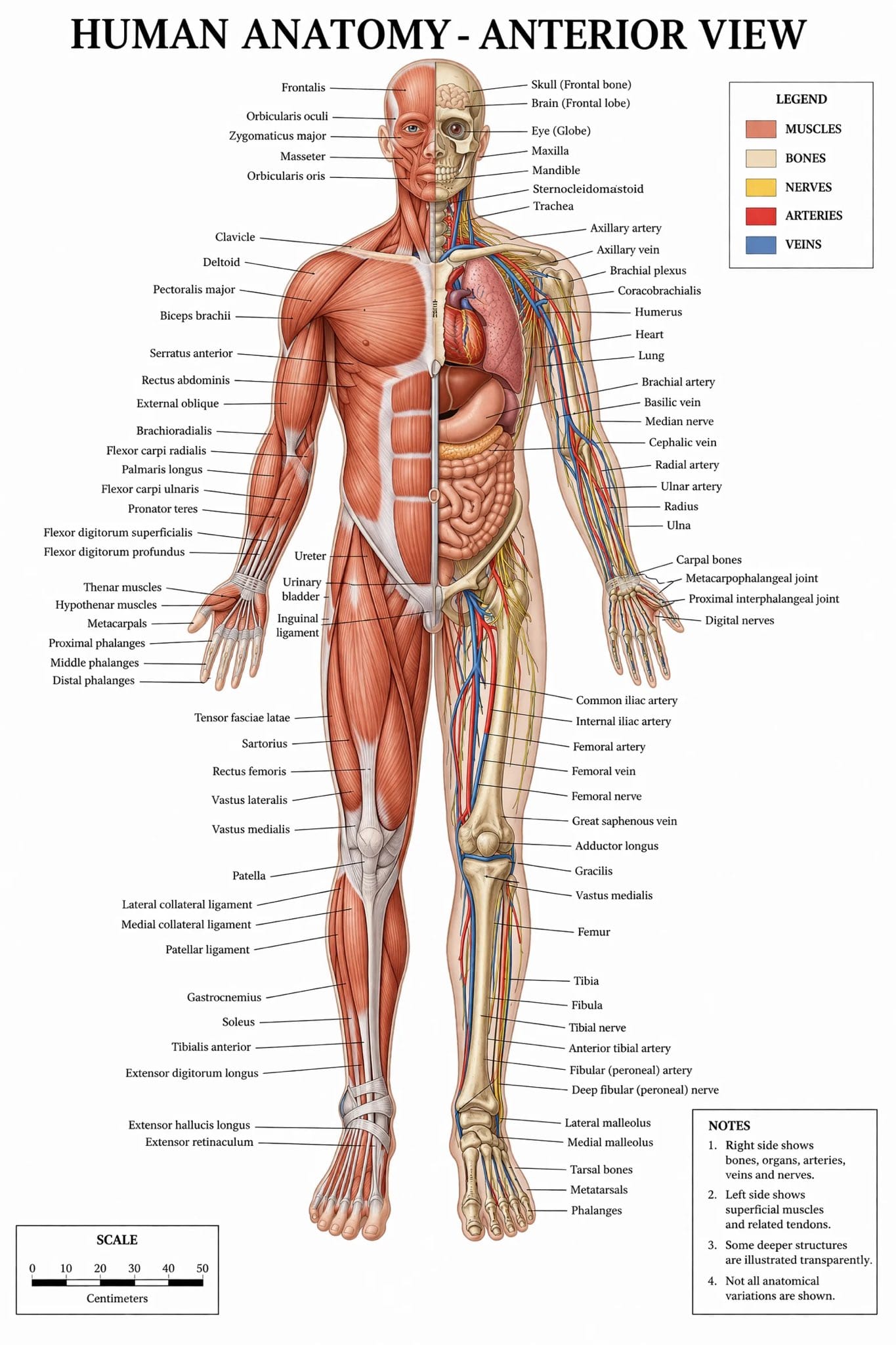
That post did two things at once. It confirmed what the early testers had been circulating, and it named the specific capabilities that mattered: world knowledge and text rendering. Two things that have let AI image models down for years. The developer and builder crowd responded immediately, because those two capabilities are the ones that actually unlock professional use cases.
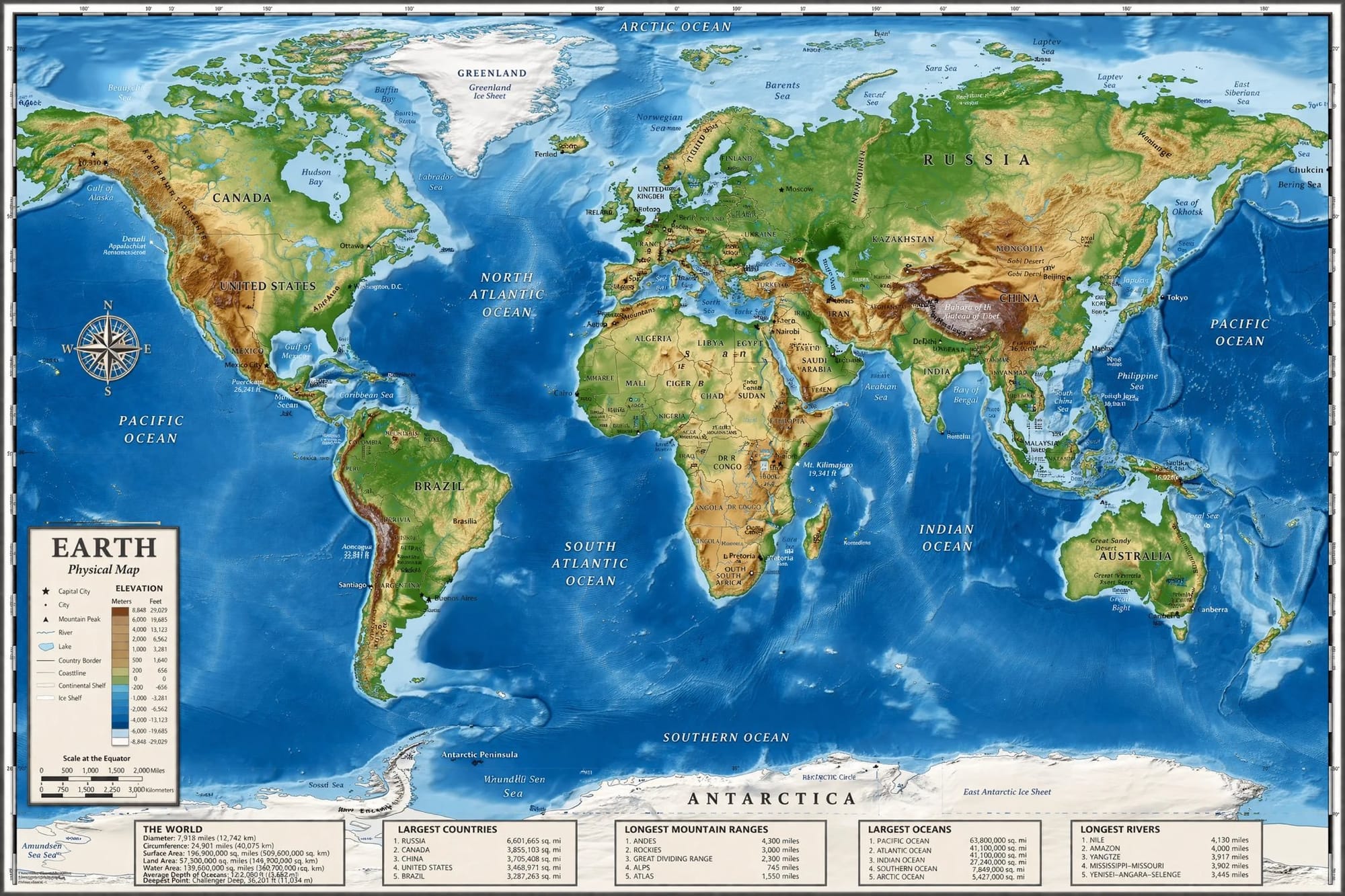
@marmaduke091 was running their own tests at the same time:
"GPT Image 2 leaked. When were you when OpenAI solved yellow filter in GPT Image? Here are some cool outputs from the model, coming soon. This looks like it's going to be the best image model yet!"
The yellow filter note matters. GPT Image 1 had a characteristic warmth in its outputs, an unnatural glow that trained eyes could spot in seconds. If that's gone, or even significantly reduced, it removes one of the most reliable tells.
What the Community Was Actually Seeing
The examples that circulated most widely fell into a few distinct categories. Each category told a different story about what GPT Image 2 is actually capable of.
Text Rendering That Holds Up at Full Zoom
This was the category that surprised people who have been following AI image generation closely. Labels on products read correctly. Signs in street scenes said coherent things. UI text inside interface mockups sat in the right place with the right visual weight. Not approximated text, not blurry placeholder glyphs, but actual readable words placed in context.
@marmaduke091 shared examples specifically highlighting this improvement, and the reaction in the replies was telling. People kept zooming in. The text held up. In AI image generation, that still counts as news.
Screens, Interfaces, and What "World Knowledge" Actually Means
The examples in this category generated the most genuine professional interest. Interface mockups. Desktop screenshots. Branded environment recreations. These prompts are notoriously difficult because they require the model to know what actual software and websites look like in practice, not just approximate visual style.
@minchoi shared outputs in this category that had the developer community paying close attention. Browser layouts, productivity tools, code editors, rendered with enough fidelity to be immediately recognizable rather than vaguely familiar.
@Gc_qube added more examples from this category, noting the consistency across different interface-style prompts. The model wasn't just getting lucky on one or two. It was handling the whole category differently than previous generations.
One specific output that circulated widely: a first person Minecraft scene set in Manhattan. Game aesthetics blended with real-world geography in a way that was both clearly referential and visually convincing. Another went viral for a different reason: a fake internal document from a fictional AI model, rendered inside a Minecraft world, which reportedly collected hundreds of thousands of views before the weekend was over.
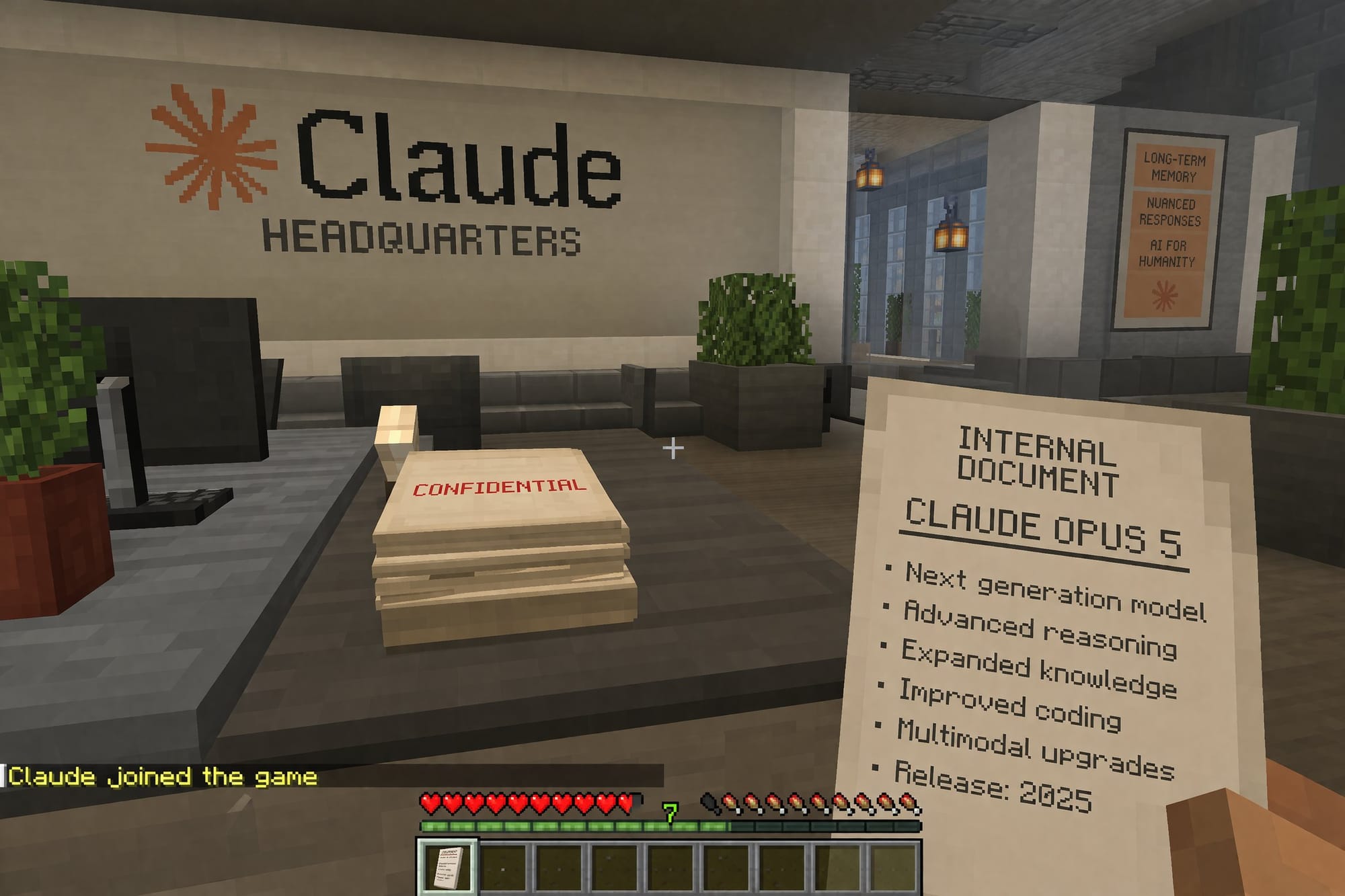
@marmaduke091 followed up specifically on this category, noting that what made it remarkable wasn't just the visual accuracy but the contextual coherence between elements. The thumbnails looked like something a real creator might upload. The interface felt like a real session, not a prop.

For anyone working in content, marketing, or product design, that class of output changes what's possible.
The Watch Face Test
One quiet benchmark that circulated in the more technical corners of the conversation: rendering a watch face showing a specific time. This has been a standard stress test for image models for years, because it requires the model to understand spatial relationships between clock hands, not just what a watch looks like generally.
The GPT Image 2 codename models, packingtape-alpha in particular, got it right. The hands pointed to the correct positions. Tested side by side with other leading image generators in the space, the gap was notable. It's a small prompt, but it's a meaningful signal about how the model understands real-world objects rather than just their visual surface.
Portrait Photorealism
@WolfRiccardo kicked off an extended multi-day testing thread that went deeper than most. He came back with follow-up posts and kept going, testing across different portrait and photography scenarios, logging where GPT Image 2 succeeded and where it didn't.

His portrait testing showed consistent improvements in three specific areas: natural lighting behavior, hand accuracy, and reflections in eyewear and surfaces. These are exactly the categories that have produced the most embarrassing failures in previous-generation image models. Getting all three right in the same output is harder than it sounds.
He continued the thread across additional posts, expanding the testing into product photography and outdoor scenes, before a final summary post that drew together his overall assessment. The pattern he documented was consistent: the model performed strongest on prompts requiring real-world contextual knowledge, and weakest on abstract spatial challenges.

That's actually a useful distinction for anyone thinking about where to apply GPT Image 2 professionally.
The Turkish Audience and Multilingual Text
@eyupyusufa brought the conversation to Turkish speaking audiences on X and highlighted a detail that hadn't gotten much coverage in English-language posts: multilingual text rendering. The model appeared to handle non-Latin scripts with more accuracy than its predecessors, rendering Turkish text cleanly inside images rather than producing the garbled approximations that have frustrated non-English users of AI image tools.

If GPT Image 2 handles multilingual text rendering at scale, that's a meaningful differentiator for international creators and brands. It's the kind of capability that looks minor in a demo but matters significantly in production.
Was It Actually a Leak?
@sterlingcrispin raised a question that a few others picked up: is this a genuine leak, or a deliberate beta test in a public-facing system?
It's worth thinking about. LM Arena is a legitimate model evaluation pipeline. Using codenames for testing is standard practice. The models were available to anyone who visited the platform during the testing window, not restricted to internal testers or NDAs. And the names, maskingtape, gaffertape, packingtape, are either a genuine attempt at obscurity or a very thin disguise.
The fact that they were removed quietly once the identification posts started spreading suggests OpenAI had a reason not to have this public yet. But the absence of a strongly worded denial also says something. The community has been interpreting that silence as a near-confirmation, and it's hard to argue with that logic.
What the Collective Reaction Tells Us
When you read through the full body of X posts about GPT Image 2, from the first discovery posts by @Angaisb_ and @synthwavedd through to the extended testing threads from @WolfRiccardo, a clear picture emerges. The reaction wasn't hype for its own sake. These are people who work with AI image generation regularly, who have calibrated expectations, and who were genuinely surprised by specific things.
The surprise wasn't about one flashy output. It was about consistency across categories that have been unreliable for years. Text rendering. Interface accuracy. Watch faces. Portrait photorealism. Multilingual output. Each of these has a specific history of failure in AI image models, and the community noticed that the history seemed to be changing.
How to Access GPT Image 2 on Eachlabs
GPT Image 2 hasn't officially launched yet, but once it becomes available on Eachlabs, you'll be able to put all of these capabilities to the test yourself. No digging through comparison threads. Just open the platform, pick the model, and start prompting. The screen mockups, the text rendering tests, the portrait photorealism. It'll all be there.
Eachlabs will be one of the first places to have it live when the official release drops.
Wrapping Up
The GPT Image 2 leak landed differently than most AI news cycles because the evidence came from real users running real tests in real time. When @blakeir called the outputs "mind-boggling," that wasn't performance. It was someone staring at three AI generated images he couldn't identify as AI generated. The breadth of the X conversation, from indie builders to investors to researchers, reflects the genuine scope of what GPT Image 2 appears to be capable of. When it officially arrives on Eachlabs, the examples you'll be able to create are going to be a different category of thing entirely.
Frequently Asked Questions
Is GPT Image 2 available to use right now?
Not officially. The codename models that appeared on Arena have since been removed, and OpenAI hasn't made a public announcement about GPT Image 2. Based on the Arena testing timeline, most analysts expect an official launch sometime between April and June 2026. Once it becomes available, you'll be able to access it on Eachlabs.
What makes GPT Image 2 different from GPT Image 1?
The most immediate difference is the yellow filter. GPT Image 1 had a warm, slightly artificial tint that trained eyes could spot instantly. That appears to be gone in GPT Image 2. Beyond the visual shift, the bigger change is in how the model handles world knowledge real brand environments, interface layouts, handwritten documents, and accurate text rendering were all weak points before. The community's reaction to the leaked Arena outputs suggests those weak points have been addressed in a meaningful way, not just patched.
What are the three codenames GPT Image 2 was tested under on Arena?
The models appeared on LM Arena as maskingtape-alpha, gaffertape-alpha, and packingtape-alpha. All three were available for blind testing before being quietly removed once the community identified them. Of the three, packingtape-alpha drew the most attention in technical testing circles, particularly for its accuracy on spatial reasoning prompts like watch face rendering.